Sentiment Analysis
Summary
In this project, the objective is to extract sentiment form more than 250000 Yelp review data. I built and trained a model that can predict rating of reviews based on the text of reviews. Another approach is to look at the polarity of words. We deployed a naive Bayes model to calculate the polarity of words.
Data format
The training data that are a series of JSON objects were downloaded from aws s3 bucket, and then converted into a list of dictionaries data using ujson library. A sample review data format is shown below:
{
'votes': {'funny': 0, 'useful': 0, 'cool': 0},
'user_id': 'tYwzsMLMc8juCuIMDAx3dw',
'review_id': 'QsrzjenckNACuOgaEiMWfA',
'stars': 4,
'date': '2011-08-18',
'text': 'Nice simple homey diner. Very friendly staff, huge family friendly menu, salad bar. If you are on the road this beats the same old options.',
'type': 'review',
'business_id': 'uGykseHzyS5xAMWoN6YUqA'
}
The target labels (i.e., stars) are pulled from data and saved in a separate list.
Data preprocessing
We slightly cleaned up the text by removing special characters:
def pre_processor(doc):
doc = re.sub("(\\W)+"," ",doc)
return doc
This function is provided as a custom preprocessing parameter of TfidfVectorizer
Feature engineering
- Stop words, tokenization and Lemmatization are done using spaCy, as shown in the snippet below.
- We considered appetence of both single words and pairs of consecutive words (bi-grams).
- Using the
__tf-idf__values of words or n-grams.
from spacy.lang.en.stop_words import STOP_WORDS
nlp = spacy.load('en')
def tokenize_lemma(text):
return [w.lemma_.lower() for w in nlp(text)]
stop_words_lemma = set(tokenize_lemma(' '.join(STOP_WORDS)))
Bigram_model
Hyperparameters
The selected hyperparameters for this model are those that control the vocabulary in the tokenization step (max_features, min_df, max_df)
and the regularization of the regression estimator (alpha). To determine these parameters we used GridSearchCV.
Data transformation
Since we aimed to predict star values of reviews based on their text, we built a custom scikit-learn transformer (ColumnSelectTransformer) that returns a list of review’s text from all records.
The snippet below shows a pipeline that will transform the data from records all the way to predictions, where the hyperparameter tuning is only operating on an Ridge estimator that was fed to GridSearchCV.
pipe_feature = Pipeline([
('column_transformer', ColumnSelectTransformer(['text'])),
('tfidf_vect', TfidfVectorizer(max_features=mf, # mf: optimal max_features
min_df=mn, # mn: optimal min_df
max_df=mx, # mx: optimal max_df
preprocessor=pre_processor,
ngram_range=(1,2),
stop_words=stop_words_lemma,
tokenizer=tokenize_lemma, token_pattern=None # or default tokenizer (sklearn)
)),
])
param_grid = {'alpha': np.logspace(-1, 1, 5)}
gs = GridSearchCV(Ridge(), param_grid)
pipe_lr = Pipeline([('feature', pipe_feature), ('lr_gs', gs)])
pipe_lr.fit(data, stars);
The estimated R2 = 0.64 and RMSE = 0.79
Word polarity
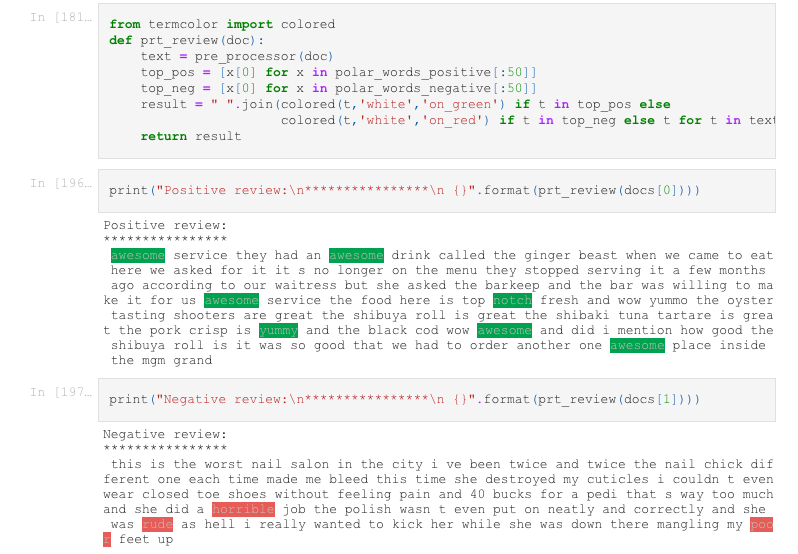
Another approach to derive some insights from our data is the Polarity Analysis which can offer a simplistic view of the sentiment information, based on the polarity of the words in a given sentence. The aim of this model is to identify the most “polarizing words” in the corpus of reviews that strongly signal positive (five-star), or negative (one-star) reviews.
Building a model
We employed naive Bayes model to calculate a polarity score for each word. Naive Bayes models can offer some major advantages, including their higher explicability compared to more complex models, they are easy to train, and a parallelizable training process.
The model is constructed using the following steps:
- Isolate the reviews with highest and lowest stars, which should contain the most polarizing words.
- Used
MultinomialNBnaive Bayes model to train on feature matrix of the most polar reviews (created by TfidfVectorizer with TF-IDF weighting and removing stop words). - Calculate the probability of words in the vocabulary, and extract the most polar ones.
Create polar data
# Create the most polar reviews and labels
pos_data = [row['text'] for row in data if row['stars'] == 5 ]
neg_data = [row['text'] for row in data if row['stars'] == 1 ]
polar_data = pos_data + neg_data
labels = ['positive'] * len(pos_data) + ['negative'] * len(neg_data)
Build a pipeline
pipe = Pipeline([
('tvec', TfidfVectorizer(
stop_words=stop_words_lemma,
)
),
('mnb', MultinomialNB())
])
pipe_parameters = {
'tvec__min_df' : [0.0001, 0.001, 0.01],
'tvec__max_df' : [0.9, 0.99, 0.999],
'tvec__max_features' : [3000, 5000]
}
gs = GridSearchCV(pipe, pipe_parameters, cv=2, n_jobs=-1)
gs.fit(polar_data, labels);
Two positve and negative reviews below contain some of top-fifty polarized positive and negative words, respectively.